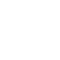Use this golden ssh command and save your valuable time
ssh -o "StrictHostKeyChecking no" -i ~/Documents/identify root@ip echo "y\n" | HOSTNAME=`hostname` ssh-keygen -t rsa -C "$HOSTNAME" -f "$HOME/.ssh/id_rsa" -P "" # copy key to remote ssh-copy-id userid@hostname sshpass -p pass ssh root@ip
You can use the @reboot keyword in crontab to start a shell script at system startup but here is why this isn’t a very good solution to do that.
The problem is that if you don’t shut down the system cleanly on the next startup this message will pop up and cron will simply skip over running your command.
"Skipping @reboot jobs -- not system startup"The solution is easy, just use a systemd service.
/etc/systemd/system/service_name.service
------------------------------------------
[Unit]
Description=some description
After=network.target
StartLimitIntervalSec=0
[Service]
Type=simple
User=root
ExecStart=/home/user/script.sh
[Install]
WantedBy=multi-user.target
UnixDaemon – How Does Cron Reboot Work
run in cmd
reg ADD HKLM\SOFTWARE\Policies\Mozilla\Firefox /v DisableAppUpdate /t REG_DWORD /d 1 /for run ff_update_dis.reg
reg ADD HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\Explorer /v NoWinKeys /t REG_DWORD /d 1 /for run win_key_dis.reg
reg ADD HKCU\Control Panel\Desktop /v AutoEndTasks /t REG_SZ /s "1" /for run win_end_task.reg
privacy.webrtc.hideGlobalIndicator
media.navigator.permission.disabled
media.
extensions.webextensions.restrictedDomains -> set to null
privacy.resistFingerprinting.block_mozAddonManager -> true
Regex, Sed, and AWK are freaks in programming but they are pretty simple, well not at the beginning though.
Here I summarize some of the most amazing ones for RegEx
I starting to use WinRT with Qt today and now after long time with MinGW, I’m switching to MSVC in Windows. Here is why
| • CoInitialize: | Initializes the COM library for use by the calling thread, sets the thread’s concurrency model, and creates a new apartment |
| • CoInitializeEx: | More advanced version CoInitialize that specify the thread’s concurrency model |
| • CoUninitialize: | Should be called on deconstructor |
Ok the title is a bit long but why google create such a nice debug interface and make it so difficult to access it.
1. open chrome with remote debug enabled
chromium --remote-debugging-port=9222 https://github.com/
2. Install websocat to create websocket to chrome
sudo pacman -S websocat
3. Find magic chrome ws url. To do that visit following url
http://127.0.0.1:9222/json/list
4. Connect to the websocket
websocat ws://127.0.0.1:9222/devtools/browser/<GUID>
5. Execute magic command. Here just scrolling the page
{"id": 1, "method": "Runtime.evaluate", "params": {"expression": "document.documentElement.scrollTop = 600"}}
http://127.0.0.1:9222/json/list or see cdp tutorial for further information.chrome_loop.sh
inotifywait -q -m -e close_write cmd | while read -r filename event; do cat cmd | websocat -n1 ws://127.0.0.1:9222/devtools/page/<GUID> done
cmd
{"id": 1, "method": "Runtime.evaluate" , "params": {"expression": "alert('hi')"}}
To calculate word level confidence score Kaldi uses a method called MBR Decoding. MBR Decoding is a decoding process that minimize word level error rate (instead of minimizing the whole utterance cost) to calculate the result. This may not give the accurate result but can be use to calculate the confidence score up to some level. Just don’t expect too much as the performance is not well-accurate.
Here are some key concepts:
1. Levenshtein Distance: Levenshtein Distance or Edit Distance compute difference between two sentences. It computes how many words are different between the two. Lets say X and Y are two word sequence shown below. The Levenshtein distance would be 3 where Ɛ represent empty word
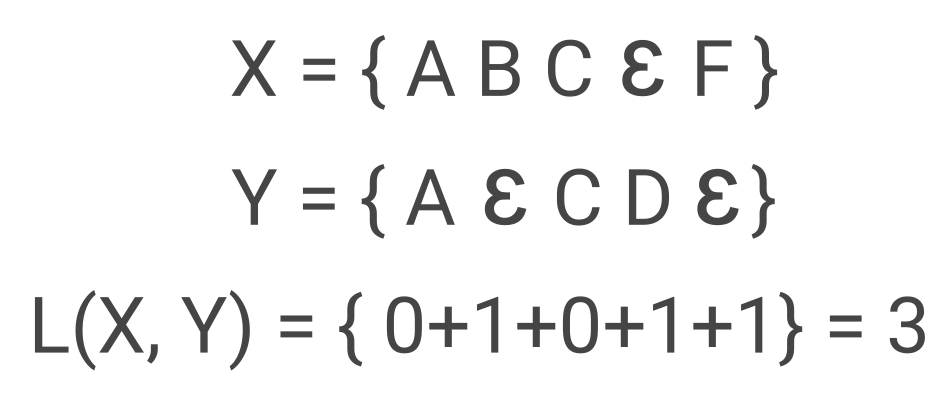
To calculate the Levenshtein distance you can use following recursive algorithm where A and B are word sequence with length of N+1
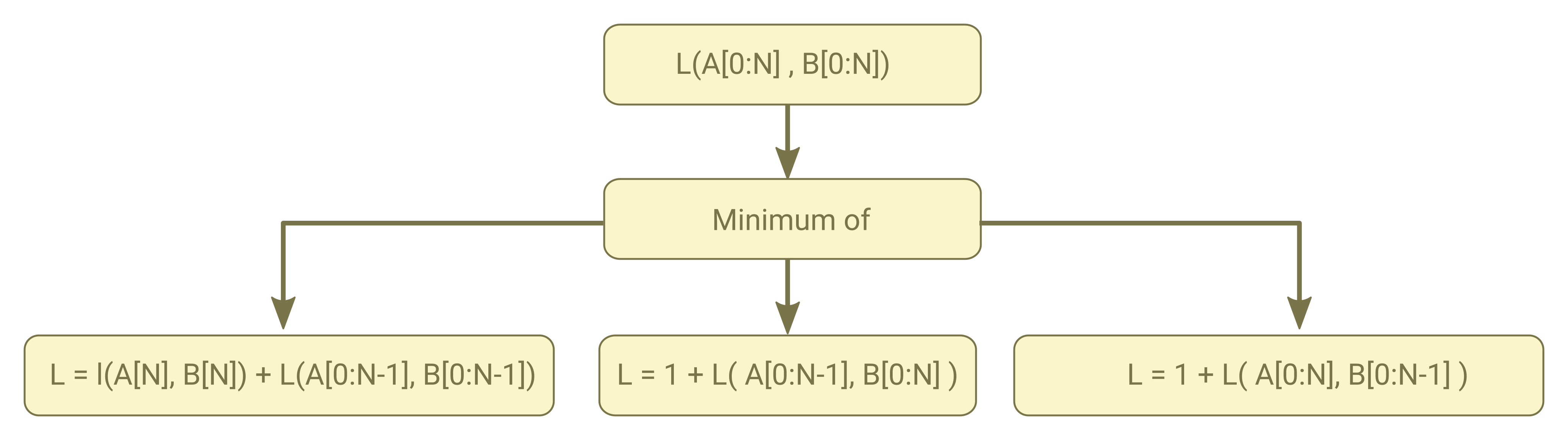
As in all recursive algorithm to decrease amount of duplicate computation Kaldi used the memoization technique and store the above three circumstances in a1, a2 and a3 respectively
2. Forward-Backward Algorithm: Lets say you want to calculate the probability of seeing a waveform(or MFCC features) given a path in a lattice (or on HHM FST). Then the Forward-Backward Algorithm is nothing more than a optimized way to compute this probability.

3. Gamma Calculation: TBA
4. MBR Decoding: TBA
Delta-Delta feature is proposed in 1986 by S. Furui and Hermann Ney in 1990. It’s simply add first and second derivative of cepstrum to the feature vector. By doing that they say it can capture spectral dynamics and improve overall accuracy.
The only problem is that in a discrete signal space getting derivative from the signal increase spontaneous noise level so instead of simple first and second order derivative HTK proposed a differentiation filter. This filter basically is a convoluted low-pass filter on top of discrete signal derivative to smooth out the result and remove unwanted noises. In Fig 1 you can see the result of simple second derivative vs the proposed differentiation filter.
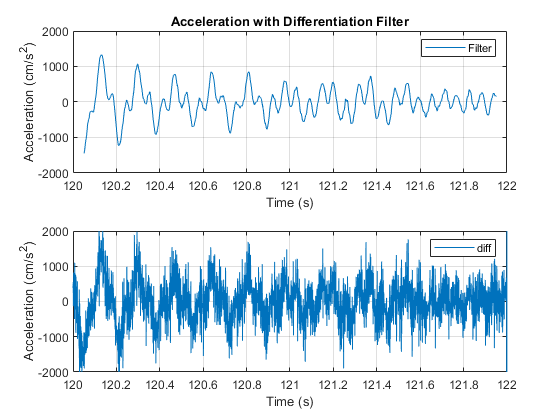
Fig. 1. Plain dervative VS differentiation filter. courtesy of Matlab™
HTK filter for a Delta-Delta feature (order=2, window=2) is a 9 element FIR filter with following coefficient(Θ is window size which is 2 in HTK)
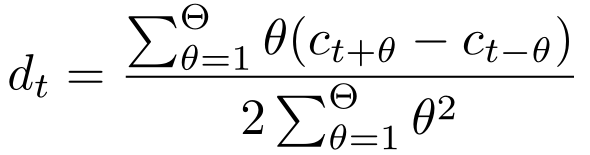
| • Reverberation: | Is the effect of sound bouncing the walls and getting back in a room. The time is roughly between 1 and 2 second in an ordinary room. You can use Sabine equation to do more accurate calculation. |
compressor filter in speech instead of CMVN to normalize in real-time.IEEE ICASSP ’86 – Isolated Word Recognition Based on Emphasized Spectral Dynamics
IEEE ICASSP ’90 – Experiments on mixture-density phoneme-modelling for 1000-word DARPA task
Desh Raj Blog – Award-winning classic papers in ML and NLP