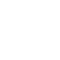This is the golden formula in the speech recognition.
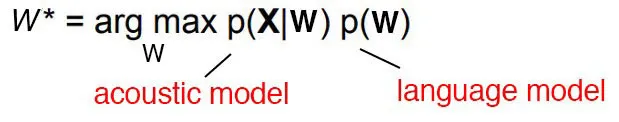
The argmax function means find the value of w that makes p(x|w) maximum. Here x is observation acoustic signal. So basically we compute all possible sequence and then for each one of them calculate the possibility of seeing such an acoustic signal. This is a very computation intensive process but by using HMM and CTC we try to minimize searching space. The process of guessing the correct sequence is called decoding in the speech recognition research field.
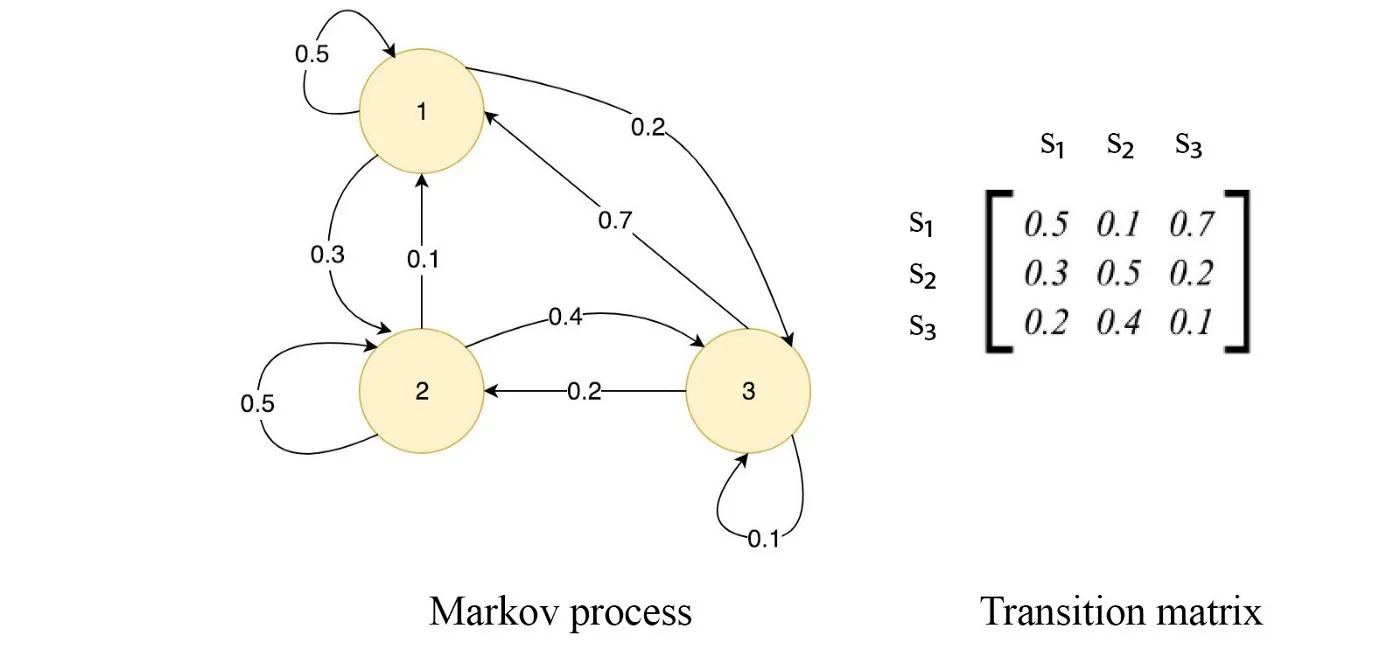
HMM is just bunch of states that transition from one state to the other. These would be called on every emitting transitions and all of them can be expressed in a matrix that would be called transition matrix.
| • Occupation counts: | .occs It’s the per-transition-id occupation counts. They are rarely needed. e.g. might be used somewhere in the basis-fMLLR scripts. |
| • FMLLR: | An acoustic feature extraction technique like MFCC but with focus on multi-speaker adaptation. |
| • Beam: | Cutoff would be Best Cost–Beam (Around 10 to 16) |
| • Deterministic FST: | A FST that each state has at most one transition with any given input label and there are no input eps-labels. |